
Большинство языковых моделей — пассивные участники своего собственного развития. Инженеры пишут код, настраивают параметры, решают когда остановить обучение. MiniMax M2.7 ломает эту парадигму: это первая модель, которая глубоко участвует в создании следующих версий себя.
Что такое самоэволюция?
Самоэволюция — это не про обучение в реальном времени и не про memory после диалога с пользователем. M2.7 статична после релиза, как любая другая LLM. Но во время разработки она активно участвует в тренировочном процессе.
Согласно MiniMax, M2.7 способна:
- Автономно управлять data pipelines
- Мониторить training environments
- Проводить evaluation infrastructure
- Запускать log-reading, debugging, metric analysis
- Применять code fixes и создавать merge requests
Цифры впечатляют
На MLE Bench Lite (22 соревнования по ML на уровне MLE-Bench от OpenAI) результаты M2.7:
- 66.6% medal rate — 9 золотых, 5 серебряных, 1 бронзовая
- Сопоставимо с Gemini-3.1 (66.6%)
- Уступает только Opus-4.6 (75.7%) и GPT-5.4 (71.2%)
Как это работает: Research Agent Harness
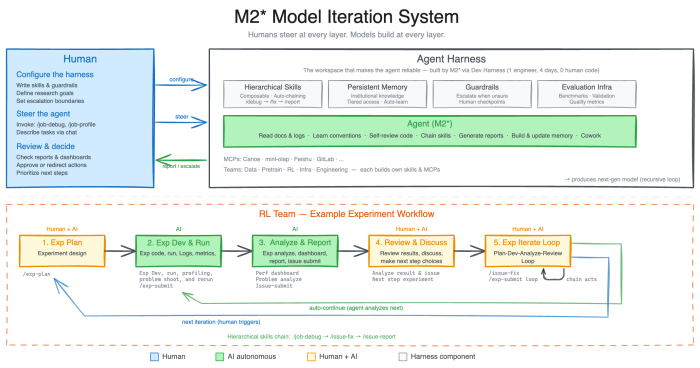
MiniMax построила внутренний research agent harness, где M2.7 управляет процессом разработки:
Типичный workflow RL-команды
- Researcher обсуждает идею эксперимента с агентом
- Agent делает literature review
- Agent отслеживает pre-set experiment spec
- Agent запускает эксперименты
- Agent мониторит прогресс и автоматически:
- Читает логи
- Делает debugging
- Анализирует метрики
- Применяет code fixes
- Создаёт merge requests
- Проводит smoke tests
- Human подключается только для критических решений
По данным MiniMax, M2.7 выполняет 30–50% этого workflow автономно.
Автономная оптимизация собственного harness
Самое интересное — M2.7 может улучшать собственный harness. Это demonstrated на примере оптимизации программирования модели:
Процесс из 100+ раундов
M2.7 полностью автономно выполнила итеративный цикл:
analyze failure trajectories
→ plan changes
→ modify scaffold code
→ run evaluations
→ compare results
→ decide to keep or revert changes
За 100+ раундов M2.7 discovered:
- Оптимальные комбинации temperature, frequency penalty, presence penalty
- Специфичные workflow guidelines (например, искать тот же баг в других файлах)
- Loop detection для оптимизации agent loop
Результат: 30% улучшение производительности на внутренних evaluation sets.
Бенчмарки и сравнение с конкурентами
| Бенчмарк | M2.7 | Сравнение |
| SWE-Pro | 56.22% | На уровне GPT-5.3-Codex |
| GDPval-AA | 1495 ELO | Высший среди open-source моделей |
| Terminal Bench 2 | 57.0% | Глубокое понимание систем |
| MMClaw | 62.7% | Близко к Sonnet 4.6 |
| Toolathon | 46.3% | Глобальный топ |
| AA-Omniscience Index | +1 | Огромный скачок с -40 у M2.5 |
| Hallucination rate | 34% | Ниже чем Sonnet 4.6 (46%) и Gemini 3.1 (50%) |
Agent Teams: мультиагентное взаимодействие
M2.7 нативно поддерживает Agent Teams — это критически важно для самоэволюции:
- Role boundaries — стабильное удержание роли
- Adversarial reasoning — оспаривание логических ошибок коллег
- Protocol adherence — соблюдение протоколов
- Behavioral differentiation — разное поведение для разных ролей
Эти способности нельзя получить через prompting — они встроены в модель на уровне архитектуры.
Почему это важно для индустрии
Сдвиг парадигмы
MiniMax M2.7 — первый сигнал перехода к моделям, которые являются архитекторами собственного прогресса. Будущее, где модели участвуют в своём развитии не менее чем люди-инженеры.
Стоимость и эффективность
Сравнение стоимости при эквивалентном уровне интеллекта:
- M2.7: $176 за стандартный intelligence index
- GLM-5: $547
- Kimi K2.5: $371
M2.7 стоит в 3 раза меньше чем GLM-5 при сопоставимом интеллекте.
Время восстановления production
В реальном production debugging M2.7 сократила время восстановления после incidents до менее чем 3 минут. Для сравнения, традиционный manual debugging занимает часы.
Ограничения и что остаётся людям
Несмотря на впечатляющие способности, граница ответственности ясна:
- Люди определяют: objectives, evaluation criteria, subjective quality
- Модель делает: operational layer, debugging, data pipeline, monitoring
Полная автономия — вопрос будущего. MiniMax прогнозирует постепенный переход к full autonomy в координации data construction, model training, inference architecture и evaluation.